Let’s look at implementing Conway’s Game of Life using a graphics card. I want to experiment with different libraries and techniques, to see how to get the best performance. I’m going to start simple, and get increasingly complex as we dive in.
The Game Of Life is a simple cellular automata, so should be really amenable to GPU acceleration. The rules are simple: Each cell in the 2d grid is either alive or dead. At each step, count the alive neighbours of the cell (including diagonals). If the cell is alive, it remains alive if 2 or 3 neighbours are alive. Otherwise it dies. If the cell is dead, it comes ot life if exactly 3 neighbours are alive. These simple rules cause an amazing amount of emergent complexity which has been written about copiously elsewhere.
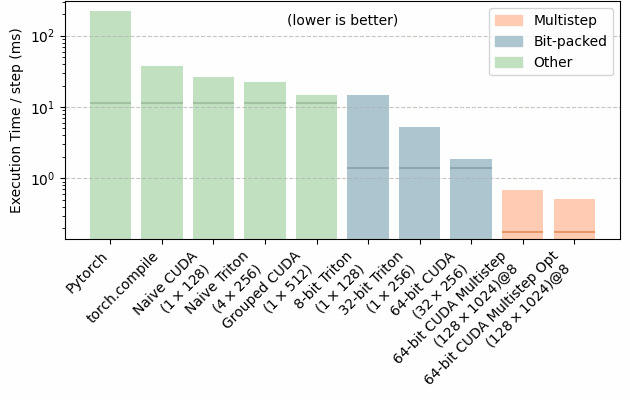
For simplicity, I’ll only consider N×N grids, and skip calculations on the boundary. I ran everything with an A40, and I’ll benchmark performance at N=216 . For now, we’ll store each cell as 1 byte so this array is which equates to 4 GB of data.
All code is shared in the GitHub repo.
Continue reading →