TranformerLens is a Python library for Mechanistic Interpretability. It’s got some great tutorials… but they are all kinda verbose. Here’s a cheatsheet of all the common things you’ll want from the library. Click the links for more details.
Table of Contents
Setup
!pip install git+https://github.com/TransformerLensOrg/TransformerLens
import transformer_lens
from transformer_lens import HookedTransformer, HookedTransformerConfig, utilsCreating a model
model = HookedTransformer.from_pretrained("gpt2-small")
cfg = HookedTransformerConfig(...)
model = HookedTransformer.from_config(cfg)Models have very similar arguments and methods to Torch modules.
Full list of pretrained models. Example parameters for HookedTransformerConfig.
Running a model
some_text = "..."
logits = model(some_text)
logits, loss = model(some_text, return_type="both")
logits, cache = model.run_with_cache(some_text)
model.generate(some_text, max_new_tokens=50, temperature=0.7, prepend_bos=True)Weights
model.blocks[0].attn.W_Q # shape (nheads, d_model, d_head)
model.W_Q # shape (nlayers, nheads, d_model, d_head)
model.b_QWeight matrices multiply on the right, i.e. they have shape [input, output],
See diagram or reference for all weights.
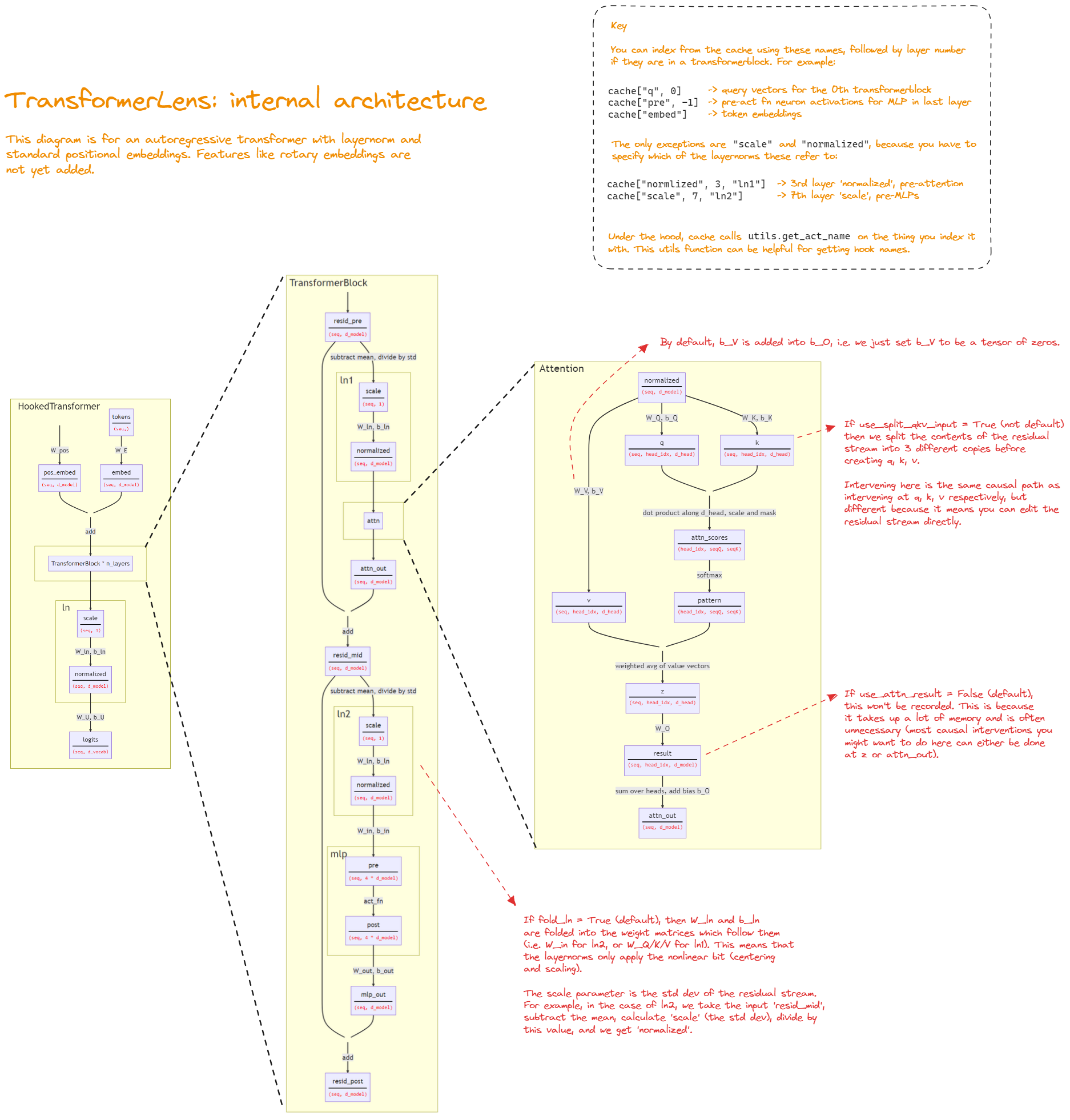{kind=link}
Working with ActivationCache
# Fully qualified
cache["blocks.0.attn.hook_pattern"]
# Short code using utils.get_act_name(name, layer[, layer_type])
layer = 0
cache["embed"] # token embeddings
cache["q", layer] # Query vectors for nth transformer block
# These two need you to say which LayerNorm they refer to
cache["normalized", layer, "ln1"]
cache["scale", layer, "ln2"]
# Final LayerNorm
cache["normalized"]
cache["scale"]Can use layer=-1 for last layer.
Full set of short names:
| Name | aka | shape (excl. batch) |
|---|---|---|
| embed | seq d_model | |
| pos_embed | seq d_model | |
| resid_pre layer | seq d_model | |
| scale layer ln1 | seq 1 | |
| normalized layer ln1 | seq d_model | |
| q layer | query | seq head_idx d_head |
| k layer | key | seq head_idx d_head |
| v layer | value | seq head_idx d_head |
| attn_scores layer | attn_logits | head_idx seqQ seqK |
| pattern layer | attn | head_idx seqQ seqK |
| z layer | seq head_idx d_head | |
| result layer | seq head_dx d_model | |
| attn_out layer | seq d_model | |
| resid_mid layer | seq d_model | |
| scale layer ln2 | seq d_model | |
| normalized layer ln2 | seq d_model | |
| pre layer | mlp_pre | seq 4*d_model |
| post layer | mlp_post | seq 4*d_model |
| mlp_out layer | seq d_model | |
| resid_post layer | seq d_model | |
| scale | seq d_model | |
| normalized | seq d_model |
See diagram for what each activation means.
All tensors start with a batch dimension, unless you ran the model with remove_batch_dim=True.
CircuitsVis
!pip install circuitsvis
import circuitsvis as cv
attn_pattern = cache["pattern", 0]
tokens = model.to_str_tokens(some_text)
cv.attention.attention_patterns(tokens=tokens, attention=attn_pattern)Hooks
head_index_to_ablate = 4
def head_ablation_hook(value: torch.Tensor, hook: HookPoint) -> torch.Tensor:
value[:, :, head_index_to_ablate, :] = 0.
return value
model.run_with_hooks(some_text, fwd_hooks=[
("blocks.0.attn.hook_v", head_ablation_hook)
])
# Multiple hook points
model.run_with_hooks(some_text, fwd_hooks=[
(lambda name: name.endswith("v"), head_ablation_hook)
])
# Using partial
from functools import partial
def head_ablation_hook2(value: torch.Tensor, hook: HookPoint, head_index: int) -> torch.Tensor:
value[:, :, head_index, :] = 0.
return value
model.run_with_hooks(some_text, fwd_hooks=[
("blocks.0.attn.hook_v", partial(head_ablation_hook2, head_index=4))
])
Don’t forget you can use utils.get_act_name to get hook names easily.
Tokens
some_text = "The fat cat"
model.get_token_position(" cat", some_text)
tokens = model.to_tokens(some_text)
model.to_string(tokens)
model.to_str_tokens(some_text)Many token methods accept str or List[str] or a tensor of Long with shape (batch, pos).
Note that a “BoS” token is prepended during tokenization, this is a common gotcha. Consider using kwarg prepend_bos=False.